选自arXiv
作者:YaoQin、GeoffreyHinton等
机器之心编译
参与:王子嘉、GeekAI
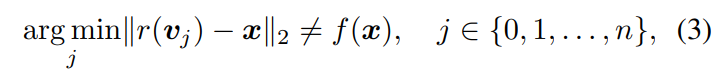
论文地址:
引言
在本文中,我们提出了一种基于胶囊层(Capsulelayer,Sabouretal.,2017;Qinetal.,2020)的网络和检测机制,它可以精确地检测到攻击,对于未检测到的攻击,它通常也可以迫使攻击者生成类似于目标类的图像(从而使它们被偏转)。我们的网络结构由两部分组成:对输入进行分类的胶囊分类网络,以及根据预测的胶囊(predictedcapsule)的姿态参数(poseparameters)重建输入图像的重建网络。

图3:具有循环一致性的胜出的胶囊重建(cycle-consistentwinningcapsulereconstructions)网络架构。
除了(Sabouretal.,2017;Qinetal.,2020)中使用的分类损失和L2重建损失外,我们还引入了一个额外的循环一致性训练损失,该训练损失迫使胜出的胶囊重建结果的分类与原始输入的分类相同。这种新的辅助训练损失促使重建更严格地匹配有类别条件的分布,而且也对模型检测和偏转对抗攻击有所帮助。
此外,我们基于对干净的输入和对抗性输入的胜出胶囊重建之间的差异,提出了两种新的攻击不可知的检测方法。我们证明,在SVHN和CIFAR-10数据集上,基于三种不同的变形度量——EAD(Chenetal.,2018)、CW(CarliniWagner,2017b)和PGD(Madryetal.,2017)证明了,该方法可以准确地检测白盒和黑盒攻击。
检测方式
在本文中,我们使用三种基于重建的检测方法来检测标准攻击。这三种方法分别是:(1)最早由Qin等人在2020年提出的全局阈值检测器(GlobalThresholdDetector,GTD),局部最优检测器(LocalBestDetector,LBD)和循环一致性检测器(Cycle-ConsistencyDetector,CCD)。
全局阈值检测器
当输入被对抗性攻击扰动时,对输入的分类结果可能是不正确的,但是重建结果常常是模糊的,因此对抗性输入和重建结果之间的距离比期望的正常输入与重建结果之间的距离要大。这使得我们可以通过全局阈值检测器检测出对抗性输入。这种Qin等人于2020年发表的论文中提出的方法,测量了输入与胜出胶囊的重建结果之间的重建误差。如果重建误差大于全局阈值θ:
那么输入就会被标记为对抗性样本。
局部最优检测器
当输入是一个干净的(clean)图像时,胜出胶囊的重建误差小于失败胶囊的重建误差,相关示例如图4的第一行所示。
然而,当输入是一个对抗示例时,与胜出的胶囊对应的重建结果相比,从对应于正确标签的胶囊进行重建的结果更接近于输入(见图4中的第二行)。

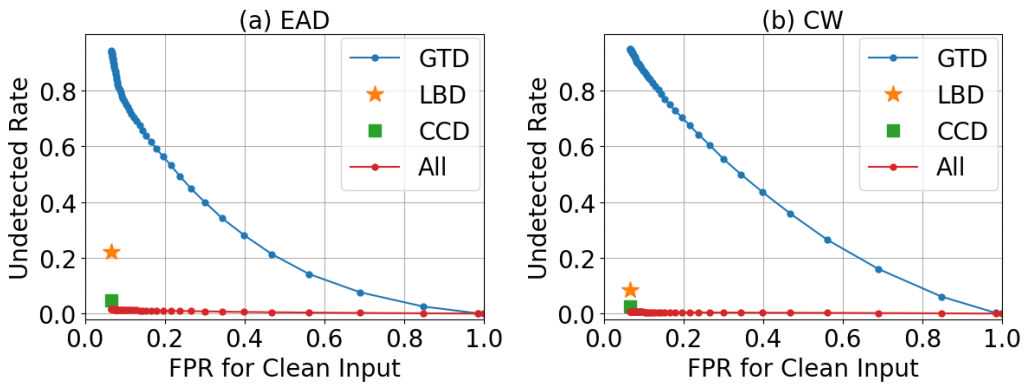
图7:在SVHN和CIFAR-10数据集上,白盒和黑盒攻击的漏检率与干净输入的假阳性率(FPR)。最强攻击的线下面积最大。
尽管我们可以清楚地看到,与标准的PGD攻击相比,CC-PGD的漏检率增加了。然而,如表1所示,在SVHN上,白盒CC-PGD的成功率却显著下降(从PGD:96.0%到CC-PGD:69.0%)。这说明攻击者需要牺牲一定的成功率才能不被我们的检测机制检测到。
表1。
从表2可以看出,虽然统计检验(Rothetal.,2019)和基于分类器的检测方法(Hosseinietal.,2019)可以成功地检测到标准攻击,但是它们对于能够感知防御的攻击的检测则都失败了。相比之下,我们提出的基于重建的检测机制在检测能够感知防御的对抗性攻击时的漏检率是最小的,在检测CW攻击方面的漏检率仅为4.6%。
表2:在CIFAR-10数据集上,与目前最先进的检测方法的漏检率的比较。
检测黑盒攻击
为了研究我们的检测机制的有效性,我们还在黑盒攻击上测试了我们的模型。在图7中,我们可以看到,在这两个数据集上,当输入为黑盒CC-PGD攻击时,漏检率仅为白盒CC-PGD的一半。
此外,如表1所示,白盒攻击和黑盒攻击的成功率有巨大差距,这就表明我们的防御模型显著降低了各种对抗性攻击的可迁移性。
偏转攻击
在SVHN上进行人工研究
为了验证我们的方法可以偏转对抗性攻击的说法,我们进行了一项人工研究。我们使用亚马逊土耳其机器人网络服务招募参与者,并要求人们标记SVHN数字。结果如图8所示。
图8:在SVHN上的人工研究结果。最大的L∞扰动为16/255。
此外,与白盒攻击相比,更多在黑盒环境下生成的未被检测到的、成功的对抗性攻击会被偏转,从而变得与目标类相似。这表明,要在更真实的场景(黑盒)下攻击我们的偏转模型,攻击将被偏转以避免被检测到,如图9所示。
图9:在SVHN和CIFAR-10上被偏转的对抗性攻击。SVHN的最大L∞扰动为16/255,CIFAR-10的最大L∞扰动为25/255。
CIFAR-10上的偏转攻击
为了证明我们的模型可以在CIFAR-10数据集上有效地偏转对抗性攻击,我们为每个类选择了一个偏转后的对抗性攻击,其最大L∞范数为25/255,如图9所示。
很明显,为了欺骗分类器和我们的检测机制,干净的输入已经被扰动,具有目标类的代表性特征。实验结果表明,我们的模型也成功地偏转了这些对抗性攻击。





